Recognizing actions without training using scene context with object recognition
- morrislee

- Oct 28, 2021
- 1 min read
Recognizing actions without training using scene context with object recognition
Zero-Shot Action Recognition from Diverse Object-Scene Compositions
arXiv paper abstract https://arxiv.org/abs/2110.13479v1
arXiv PDF paper https://arxiv.org/pdf/2110.13479v1.pdf
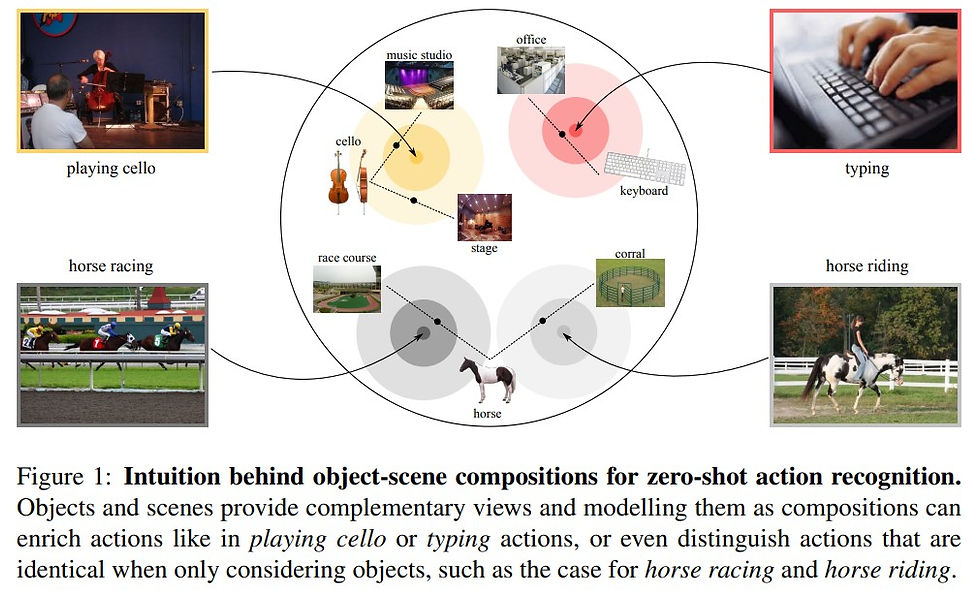
... investigates the problem of zero-shot action recognition, in the setting where no training videos with seen actions are available.
... current leading approach is to transfer knowledge from the image domain by recognizing objects in videos ... followed by a semantic matching between objects and actions.
... in this work we also seek to include a global view of the scene in which actions occur.
... To get the best out of objects and scenes, we propose to construct them as a Cartesian product of all possible compositions.
... outline how to determine the likelihood of object-scene compositions in videos
... composition-based approach outperforms object-based approaches and even state-of-the-art zero-shot approaches that rely on large-scale video datasets with hundreds of seen actions for training and knowledge transfer.
Please like and share this post if you enjoyed it using the buttons at the bottom!
Stay up to date. Subscribe to my posts https://morrislee1234.wixsite.com/website/contact
Web site with my other posts by category https://morrislee1234.wixsite.com/website




Comments