Survey of vision-language models for vision tasks
- morrislee

- Apr 4, 2023
- 1 min read
Survey of vision-language models for vision tasks
Vision-Language Models for Vision Tasks: A Survey
arXiv paper abstract https://arxiv.org/abs/2304.00685
arXiv PDF paper https://arxiv.org/pdf/2304.00685.pdf
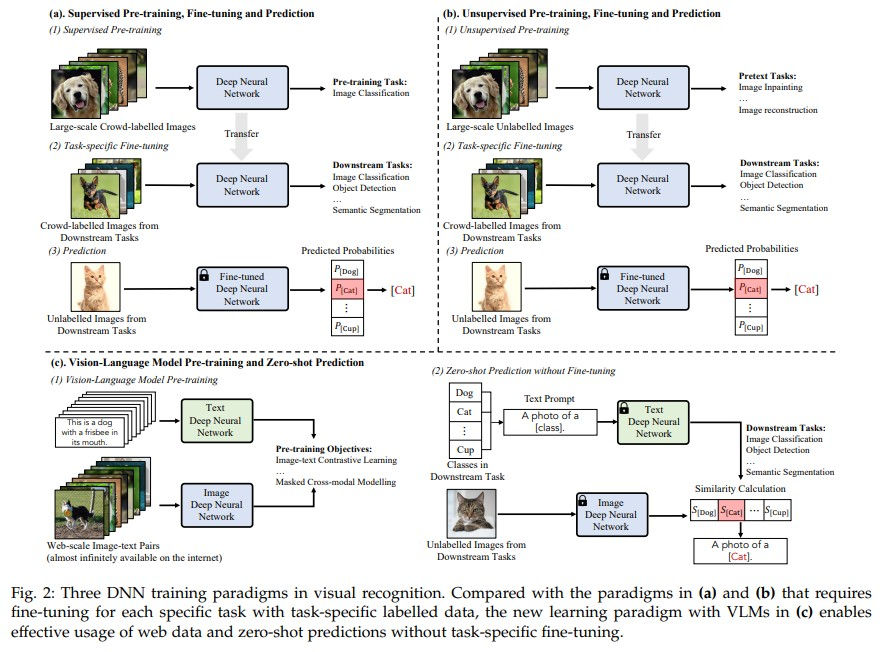
Most visual recognition ... rely ... on crowd-labelled data ... and ... train ... for each single visual recognition task, leading to a laborious ... paradigm.
To address the two challenges, Vision-Language Models (VLMs) ... learns ... vision-language correlation from web-scale image-text pairs ... infinitely available on the Internet and enables zero-shot predictions on various visual recognition tasks with a single VLM.
This paper provides a systematic review of visual language models for various visual recognition tasks, including:
(1) the background that introduces the development of visual recognition paradigms;
(2) the foundations of VLM that summarize the widely-adopted network architectures, pre-training objectives, and downstream tasks;
(3) the widely-adopted datasets in VLM pre-training and evaluations;
(4) the review and categorization of existing VLM pre-training methods, VLM transfer
learning methods, and VLM knowledge distillation methods;
(5) the benchmarking, analysis and discussion of the reviewed methods;
(6) several research challenges and potential research directions that could be pursued in the future VLM studies for visual recognition.
Please like and share this post if you enjoyed it using the buttons at the bottom!
Stay up to date. Subscribe to my posts https://morrislee1234.wixsite.com/website/contact
Web site with my other posts by category https://morrislee1234.wixsite.com/website




Comments